Grounding Language Models to Images for Multimodal Inputs and Outputs
ICML 2023
| Jing Yu Koh | Ruslan Salakhutdinov | Daniel Fried |
|---|
| Carnegie Mellon University |
|---|
Abstract
We propose an efficient method to ground pretrained text-only language models to the visual domain, enabling them to process and generate arbitrarily interleaved image-and-text data. Our method leverages the abilities of language models learnt from large scale text-only pretraining, such as in-context learning and free-form text generation. We keep the language model frozen, and finetune input and output linear layers to enable cross-modality interactions. This allows our model to process arbitrarily interleaved image-and-text inputs, and generate free-form text interleaved with retrieved images. We achieve strong zero-shot performance on grounded tasks such as contextual image retrieval and multimodal dialogue, and showcase compelling interactive abilities. Our approach works with any off-the-shelf language model and paves the way towards an effective, general solution for leveraging pretrained language models in visually grounded settings.

Model

FROMAGe (Frozen Retrieval Over Multimodal Data for Autoregressive Generation) is a model trained on image-text pairs on a multi-objective loss of image captioning and image-text retrieval.
It is capable of processing arbitrarily interleaved image and text inputs, and producing interleaved images and text as outputs. FROMAGe is capable of a variety of zero-shot and few-shot image-text tasks.
Capabilities
FROMAGe is capable of producing compelling few-shot results on various image-text tasks. Images shown are retrieved from the Conceptual Captions dataset. More qualitative results are provided in our paper.
Concept Composition
FROMAGe can seamlessly composite image and text data to retrieve images with the desired style or content. Note that the objects ("motorcycle" and "cat") are never explicitly mentioned in text.


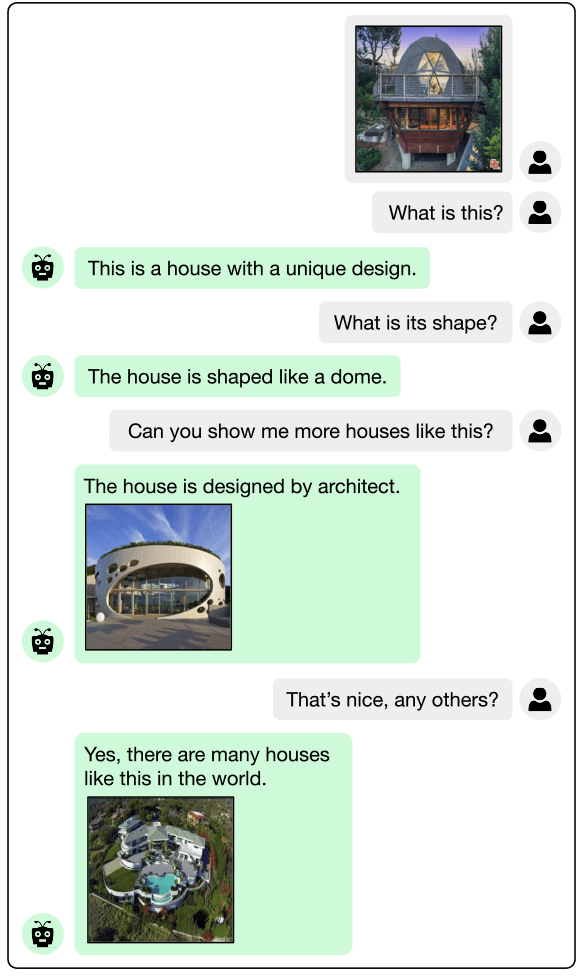
Multimodal Dialogue
FROMAGe can generate multimodal dialogue, processing arbitrarily interleaved image-and-text inputs, and producing image-and-text outputs. Green bubbles indicate model generated outputs, grey bubbles indicate user provided prompts.

World Knowledge
Our model is able to draw upon knowledge about the world learnt through large scale text-only pretraining of its frozen large language model.

In-context Learning and More
Our model is able to perform many more interesting and compelling image-text tasks. More qualitative results are provided in our paper and appendix.
Limitations
FROMAGe is one of the first models to be able to both process and produce image-text data. We believe that it is a promising step towards such multimodal capabilities and systems. Nevertheless, it exhibits several important limitations, that we briefly describe here, and go into more detail in our paper and appendix:
- We find that FROMAGe does not always generate [RET] tokens during inference, and generally has a stronger bias to produce regular text tokens. This is likely due to its comprehensive pretraining regime (on text-only data). Investigating ways to enable FROMAGe to generate [RET] more naturally interleaved with text is also a promising direction for future work.
- FROMAGe retrieves images from the Conceptual Captions training set, which limits its ability to produce truly novel and specific images.
- Our model inherits some of the unintended behaviors of large language models, such as making up facts, ignoring user prompts, or generating incoherent and repetitive text. This is likely to be alleviated by future LLM advances and methods.
Paper

|
Grounding Language Models to Images for Multimodal Inputs and Outputs
Jing Yu Koh, Ruslan Salakhutdinov, Daniel Fried. ICML, 2023. [arXiv] |
Citation
@article{koh2023grounding, title={Grounding Language Models to Images for Multimodal Inputs and Outputs}, author={Koh, Jing Yu and Salakhutdinov, Ruslan and Fried, Daniel}, journal={ICML}, year={2023} }
Acknowledgements
This work was partially supported by a gift from Google on Action, Task, and User Journey Modeling, and supported in part by ONR N000142312368 and DARPA/AFRL FA87502321015. We thank Wendy Kua for help with the figures, and Santiago Cortés, Paul Liang, Martin Ma, So Yeon Min, Brandon Trabucco, Saujas Vaduguru, and others for feedback on previous versions of this paper. We thank Felix Hill for insightful discussions about Frozen. Icons from FontAwesome and flaticon.com.