Generating Images with Multimodal Language Models
NeurIPS 2023
Abstract
We propose a method to fuse frozen text-only large language models (LLMs) with pre-trained image encoder and decoder models, by mapping between their embedding spaces. Our model demonstrates a wide suite of multimodal capabilities: image retrieval, novel image generation, and multimodal dialogue. Ours is the first approach capable of conditioning on arbitrarily interleaved image and text inputs to generate coherent image (and text) outputs. To achieve strong performance on image generation, we propose an efficient mapping network to ground the LLM to an off-the-shelf text-to-image generation model. This mapping network translates hidden representations of text into the embedding space of the visual models, enabling us to leverage the strong text representations of the LLM for visual outputs. Our approach outperforms baseline generation models on tasks with longer and more complex language. In addition to novel image generation, our model is also capable of image retrieval from a prespecified dataset, and decides whether to retrieve or generate at inference time. This is done with a learnt decision module which conditions on the hidden representations of the LLM. Our model exhibits a wider range of capabilities compared to prior multimodal language models. It can process image-and-text inputs, and produce retrieved images, generated images, and generated text — outperforming non-LLM based generation models across several text-to-image tasks that measure context dependence.

Model
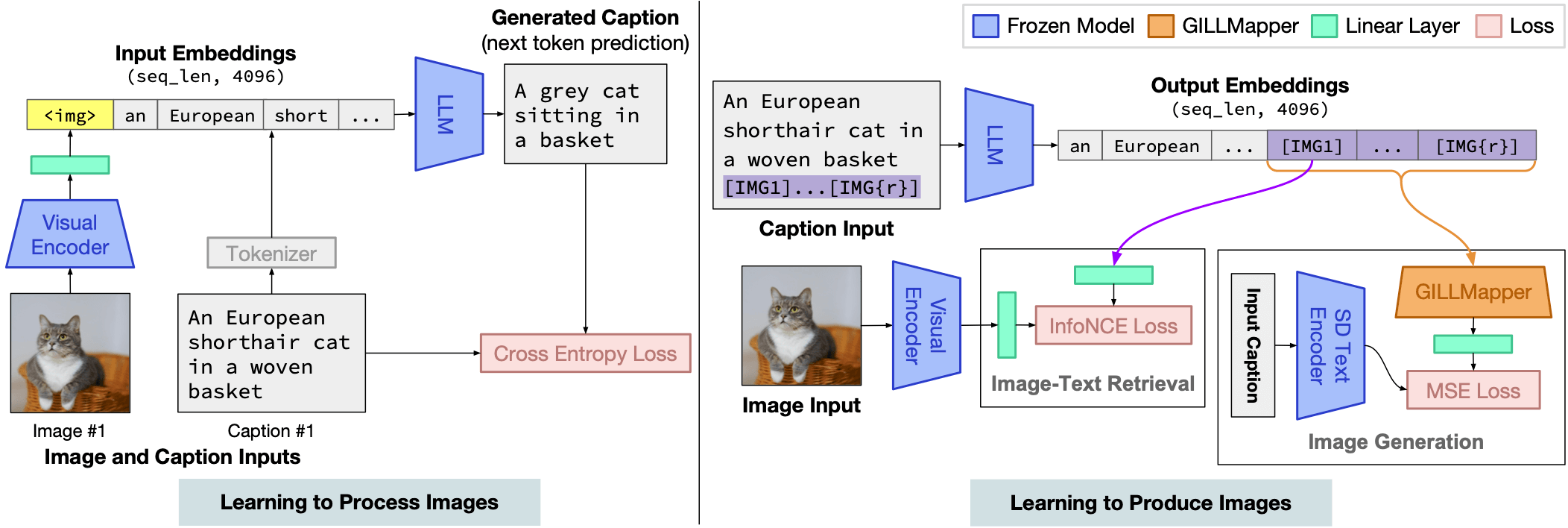
GILL (Generating Images with Large Language Models) is capable of processing arbitrarily interleaved image-and-text inputs to generate text, retrieve images, and generate novel images.
Our findings show that it is possible to efficiently map the output embedding space of a frozen text-only LLM to the embedding space of a frozen text-to-image generation model (in this work, Stable Diffusion) despite both models using entirely different text encoders. We achieve this by finetuning a small number of parameters on image-caption pairs, in contrast to other methods which require interleaved image-text training data. Our approach is computationally efficient and does not require running the image generation model at training time.
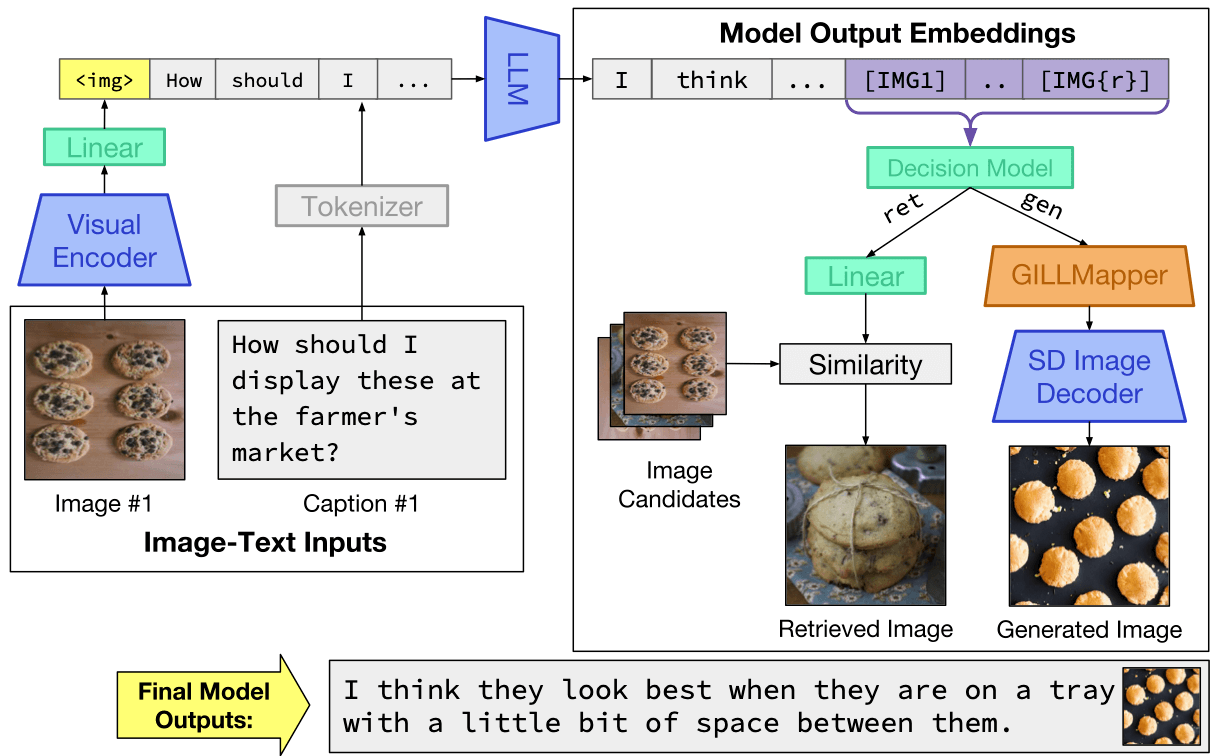
During inference, the model takes in arbitrarily interleaved image and text inputs, and produces text interleaved with image embeddings. After deciding whether to retrieve or generate for a particular set of tokens, it returns the appropriate image outputs (either retrieved or generated).
Capabilities
One of the more compelling applications of GILL is perhaps its ability to generalize to many different tasks, due to the LLM pretraining and freezing. We showcase several of these capabilities below. More qualitative results are provided in our paper.
Multimodal Dialogue Generation
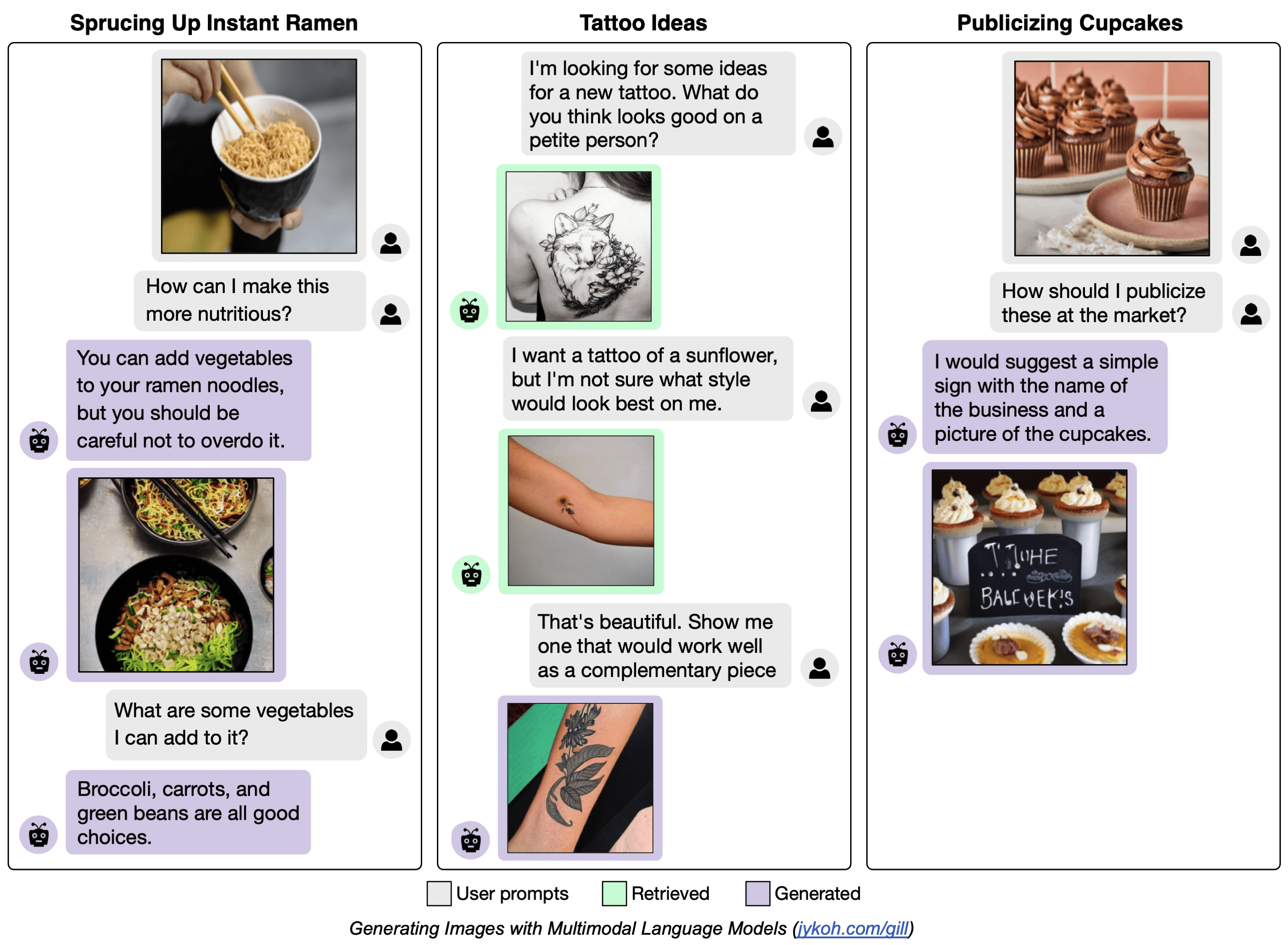
Generating from Visual Stories

GILL can condition on interleaved image-and-text inputs to generate more relevant images compared to non-LLM based text-to-image generation models.
Comparison Against Stable Diffusion

The GILLMapper module we introduce allows our model to map effectively to the SD image generation backbone, outperforming or matching SD for many examples from PartiPrompts.
Comparison Against FROMAGe

Our model composites multimodal information to produce relevant image and text outputs. It can outperform baseline models that are limited to image retrieval.
Limitations
While GILL introduces many exciting capabilities, it is an early research prototype and has several limitations. GILL relies on an LLM backbone for many of its capabilities. As such, it also inherits many of the limitations that are typical of LLMs. More details and discussion are provided in our paper and appendix:
- GILL does not always produce images when prompted, or when it is (evidently) useful for the dialogue.
- A limitation of GILL is in its limited visual processing. At the moment, we use only 4 visual vectors to represent each input image (due to computational constraints), which may not capture all the relevant visual information needed for downstream tasks.
- Our model inherits some of the unintended behaviors of LLMs, such as the potential for hallucinations, where it generates content that is false or not relevant to the input data. It also sometimes generates repetitive text, and does not always generate coherent dialogue text.
Paper

|
Generating Images with Multimodal Language Models
Jing Yu Koh, Daniel Fried, and Ruslan Salakhutdinov. NeurIPS, 2023. [arXiv] |
Citation
@article{koh2023generating, title={Generating Images with Multimodal Language Models}, author={Koh, Jing Yu and Fried, Daniel and Salakhutdinov, Ruslan}, journal={NeurIPS}, year={2023} }
Acknowledgements
This work was partially supported by a gift from Cisco Systems, and by ONR N000142312368 and DARPA/AFRL FA87502321015. We thank Wendy Kua for help with the figures. We thank Jared Fernandez, Yutong He, Saujas Vaduguru, Yonatan Bisk, and others for feedback and helpful discussions on previous versions of this paper. Icons from FontAwesome and flaticon.com.