VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
ACL 2024

Autonomous agents capable of planning, reasoning, and executing actions on the web offer a promising avenue for automating computer tasks. However, the majority of existing benchmarks primarily focus on text-based agents, neglecting many natural tasks that require visual information to effectively solve. Given that most computer interfaces cater to human perception, visual information often augments textual data in ways that text-only models struggle to harness effectively. To bridge this gap, we introduce VisualWebArena, a benchmark designed to assess the performance of multimodal web agents on realistic visually grounded tasks. VisualWebArena comprises of a set of diverse and complex web-based tasks that evaluate various capabilities of autonomous multimodal agents. To perform on this benchmark, agents need to accurately process image-text inputs, interpret natural language instructions, and execute actions on websites to accomplish user-defined objectives. We conduct an extensive evaluation of state-of-the-art LLM-based autonomous agents, including several multimodal models. Through extensive quantitative and qualitative analysis, we identify several limitations of text-only LLM agents, and reveal gaps in the capabilities of state-of-the-art multimodal language agents. VisualWebArena provides a framework for evaluating multimodal autonomous language agents, and offers insights towards building stronger autonomous agents for the web.
Example VWA Tasks
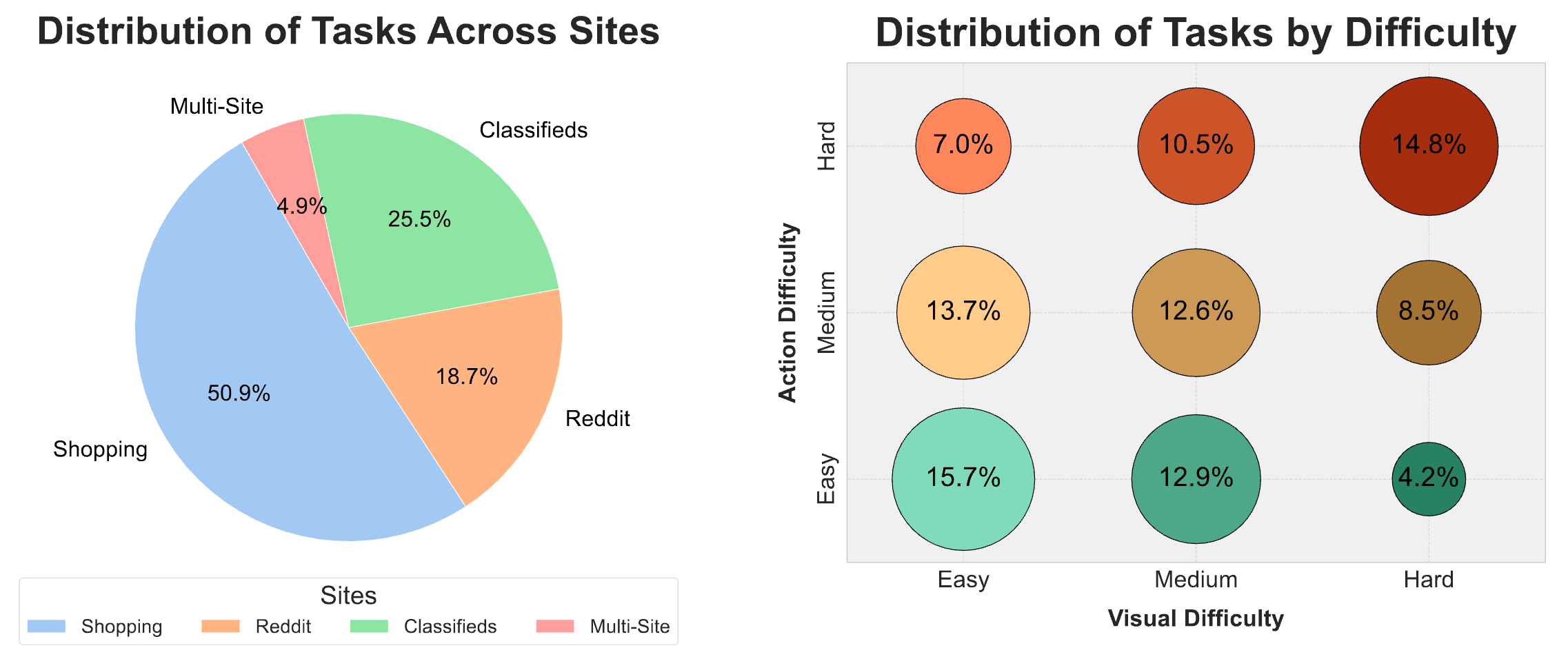
We introduce a set of 910 new tasks, split across the Classifieds, Shopping, and Reddit sites detailed above. The Classifieds website is a new environment (with real world data), while the Shopping and Reddit sites are the same ones used in WebArena.
The new tasks we introduce necessitate visual comprehension, and are designed to assess the visual and reasoning skills of autonomous agents in web-based environments. The full set of tasks can be found on our GitHub repo.
Several example tasks from the VWA benchmark are showcased below. The videos are best viewed in fullscreen mode.
Try the environments yourself!
Note: these websites are just for demo purposes, and they should not be used for evaluation as they are public. For evaluating an agent on VWA, we advise you to set up a copy of these environments locally.
Execution-Based Evaluation

In order to evaluate performance on VisualWebArena, we introduce new visually grounded evaluation metrics to the functional evaluation paradigm of WebArena. These allow us to comprehensively evaluate the correctness of agent trajectories on open ended visually grounded tasks by running execution-based tests. Several evaluation examples are shown in the figure above.
Set-of-Marks Representation for Improved Navigability
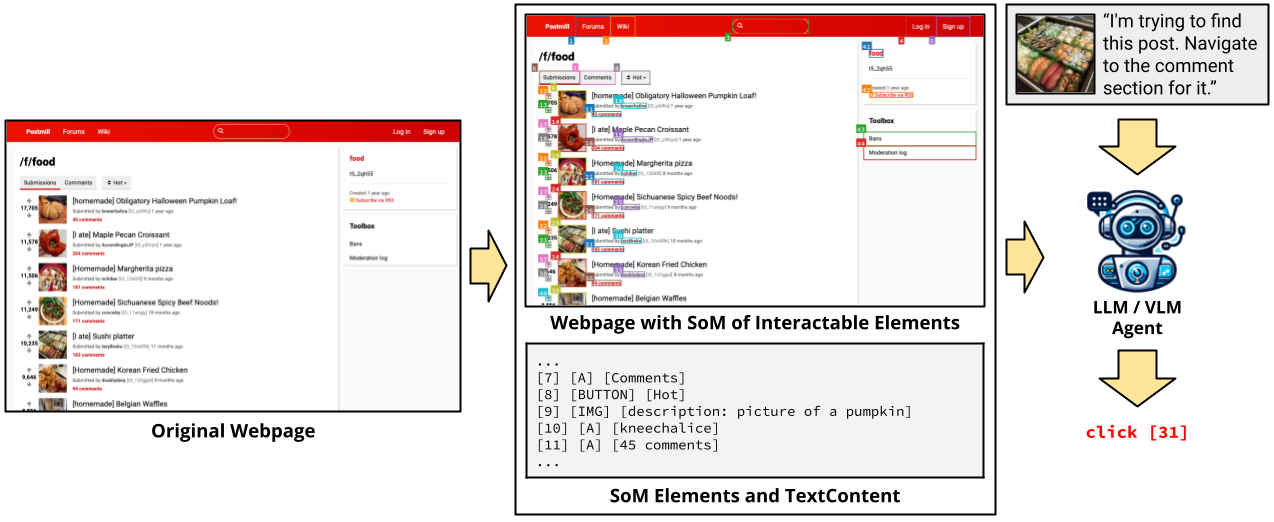
Inspired by Set-of-Mark prompting, we perform an initial preprocessing step by using JavaScript to automatically annotate every interactable element on the webpage with a bounding box and a unique ID. The annotated screenshot containing bounding boxes and IDs, are provided as input to the multimodal model along with a text representation of the SoM (see figure above). There have been several approaches that propose similar representations (e.g., GPT-4V-ACT and vimGPT). Most have been proof-of-concept demos, and to the best of our knowledge, we are the first to systematically benchmark this on a realistic and interactive web environment.
Our results (below) showcase that the SoM representation improves navigability and achieves a higher success rate on VisualWebArena.
Baseline LLM and VLM Agents
We benchmark several state-of-the-art LLM and VLM prompt-based agents. We find that all existing models are significantly below human performance. Multimodal models generally improve performance on VisualWebArena, but there remains a large gap to be closed.
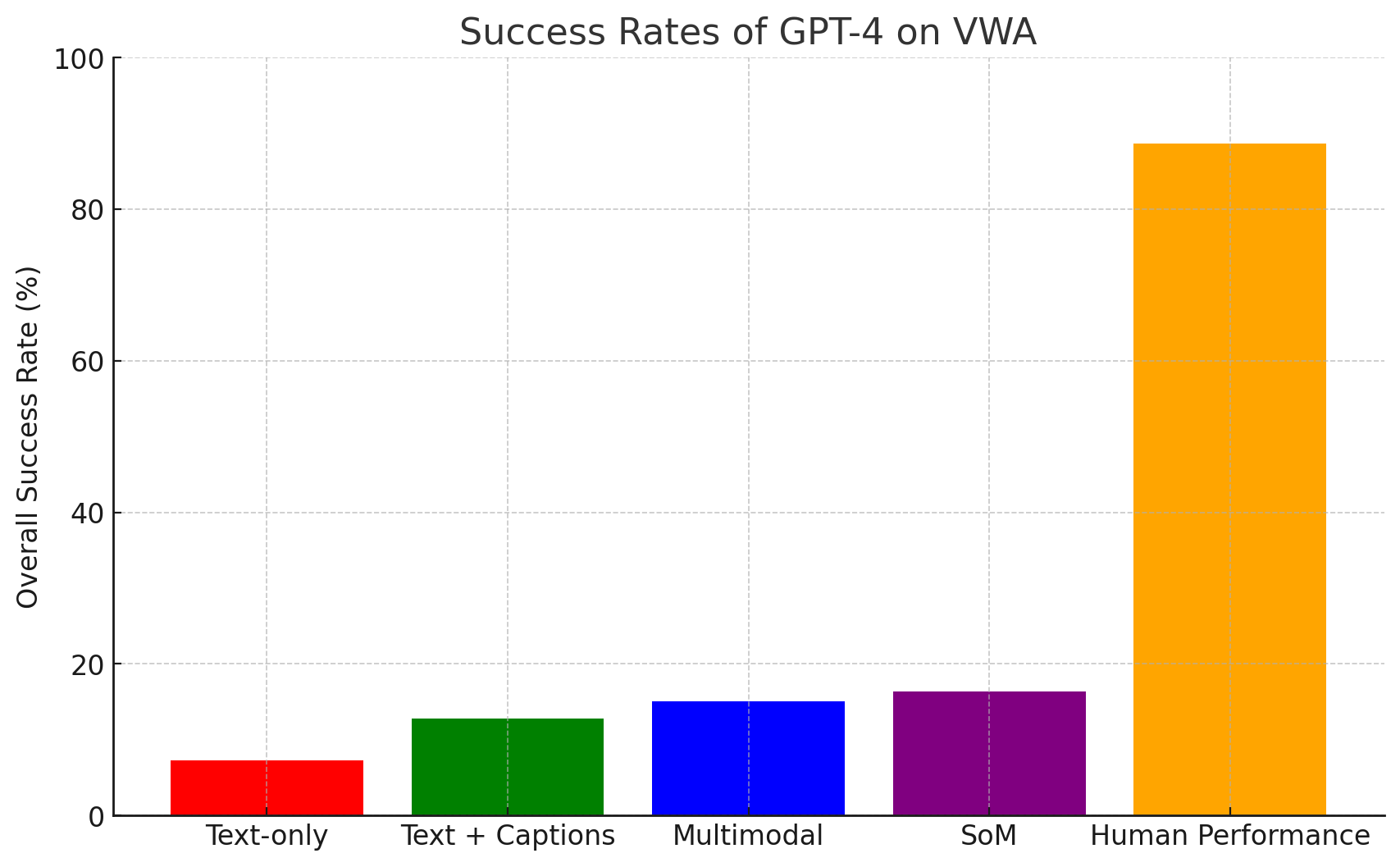
| Model Type | LLM Backbone | Visual Backbone | Inputs | Success Rate (↑) | |
|---|---|---|---|---|---|
| Text-only | LLaMA-2-70B | - | Accessibility Tree | 1.10% | |
| Mixtral-8x7B | 1.76% | ||||
| Gemini-Pro | 2.20% | ||||
| GPT-3.5 | 2.20% | ||||
| GPT-4 | 7.25% | ||||
| Caption-augmented | LLaMA-2-70B | BLIP-2-T5XL | Accessibility Tree + Captions | 0.66% | |
| Mixtral-8x7B | BLIP-2-T5XL | 1.87% | |||
| GPT-3.5 | LLaVA-7B | 2.75% | |||
| GPT-3.5 | BLIP-2-T5XL | 2.97% | |||
| Gemini-Pro | BLIP-2-T5XL | 3.85% | |||
| LLaMA-3-70B-Instruct | BLIP-2-T5XL | 9.78% | |||
| GPT-4 | BLIP-2-T5XL | 12.75% | |||
| Multimodal | IDEFICS-80B-Instruct | Image + Captions + Accessibility Tree | 0.77% | ||
| CogVLM | 0.33% | ||||
| Gemini-Pro | 6.04% | ||||
| GPT-4V | 15.05% | ||||
| Multimodal (SoM) | IDEFICS-80B-Instruct | Image + Captions + SoM | 0.99% | ||
| CogVLM | 0.33% | ||||
| Gemini-Pro | 5.71% | ||||
| Gemini-Flash-1.5 | 6.59% | ||||
| Gemini-Pro-1.5 | 11.98% | ||||
| GPT-4V | 16.37% | ||||
| GPT-4o | 19.78% | ||||
| Human Performance | - | Webpage | 88.70% | ||
Paper

|
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
Jing Yu Koh, Robert Lo*, Lawrence Jang*, Vikram Duvvur*, Ming Chong Lim*, Po-Yu Huang*, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov,and Daniel Fried. ACL, 2024. [arXiv] |
Citation
@article{koh2024visualwebarena, title={VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks}, author={Koh, Jing Yu and Lo, Robert and Jang, Lawrence and Duvvur, Vikram and Lim, Ming Chong and Huang, Po-Yu and Neubig, Graham and Zhou, Shuyan and Salakhutdinov, Ruslan and Fried, Daniel}, journal={ACL}, year={2024} }
Acknowledgements
We thank photographers on Pexels.com for providing free to use images. We thank Wendy Kua for assisting with measuring human performance and for help with the figures. We thank Yi Tay, Zhiruo Wang, Saujas Vaduguru, Paul Liang, Stephen McAleer, and many others for feedback and helpful discussions on previous versions of the paper.