
Selected Publications
See full list on Google Scholar
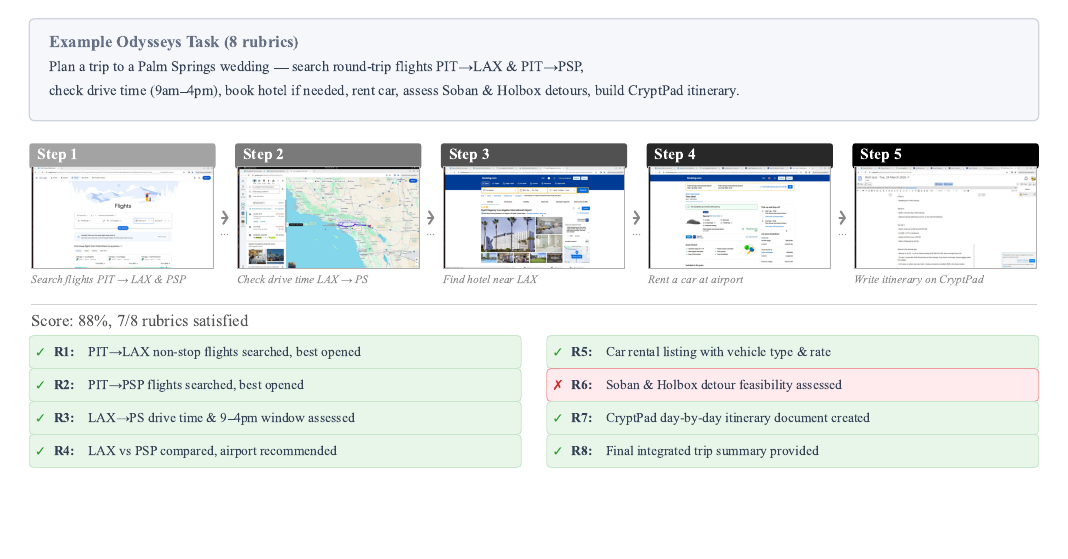
2026
2025
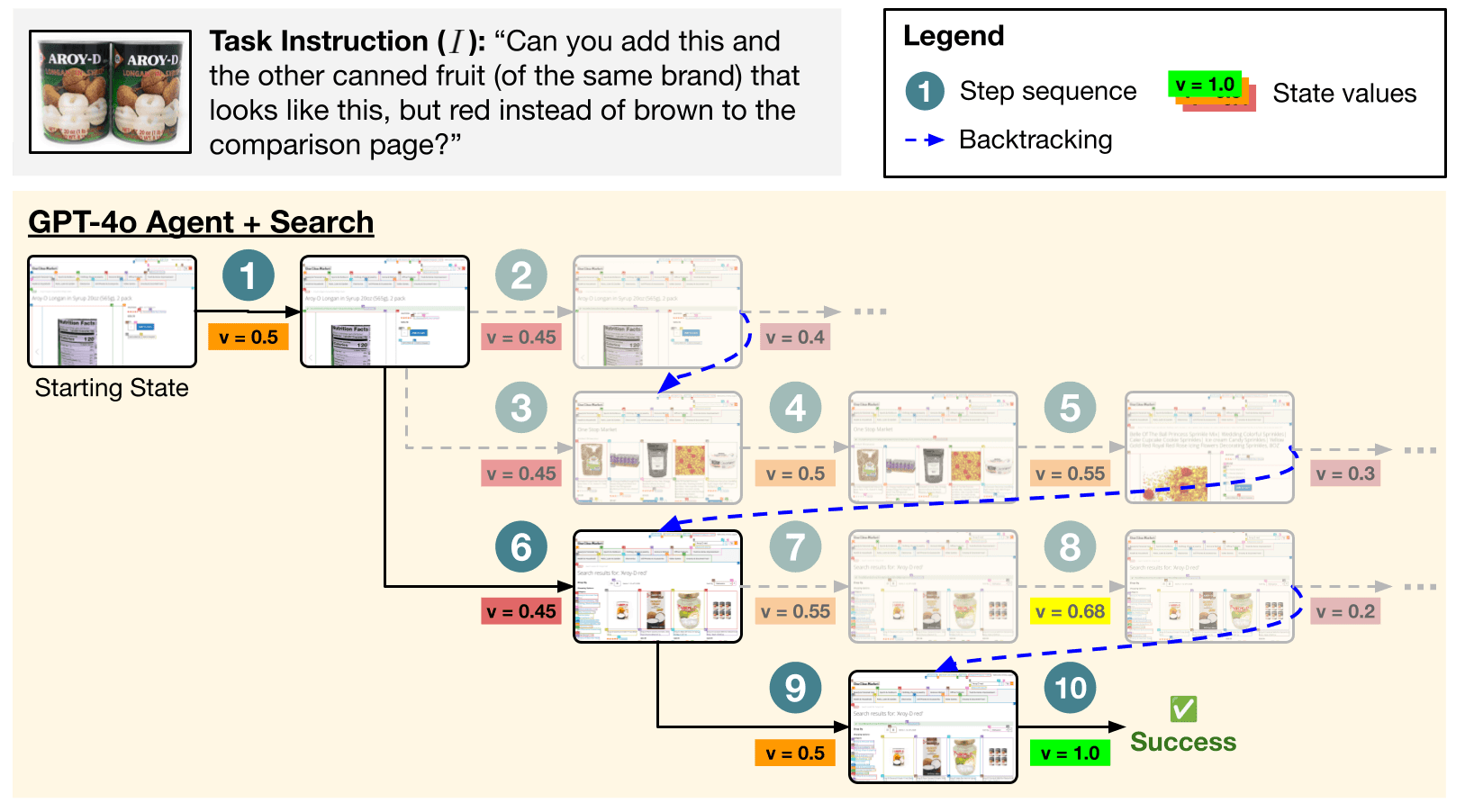
2024
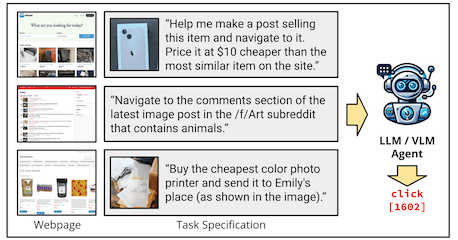
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
ACL, 2024. As seen on: Wired.
2023
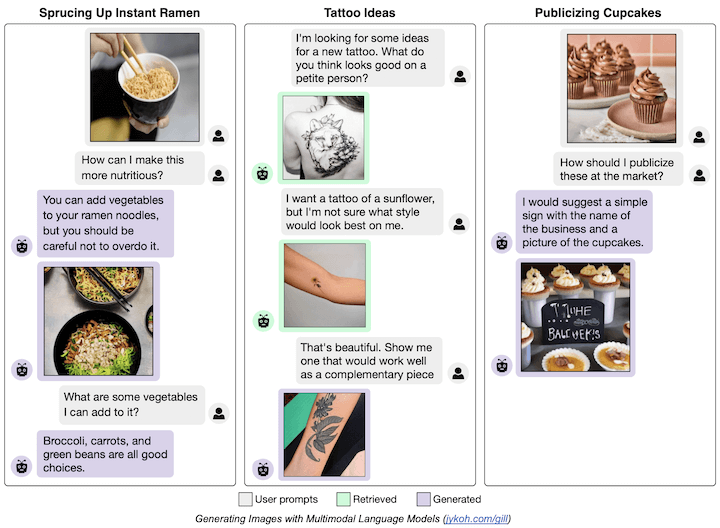

Grounding Language Models to Images for Multimodal Inputs and Outputs
ICML, 2023.

VQ3D: Learning a 3D-Aware Generative Model on ImageNet
ICCV (oral, best paper finalist), 2023.
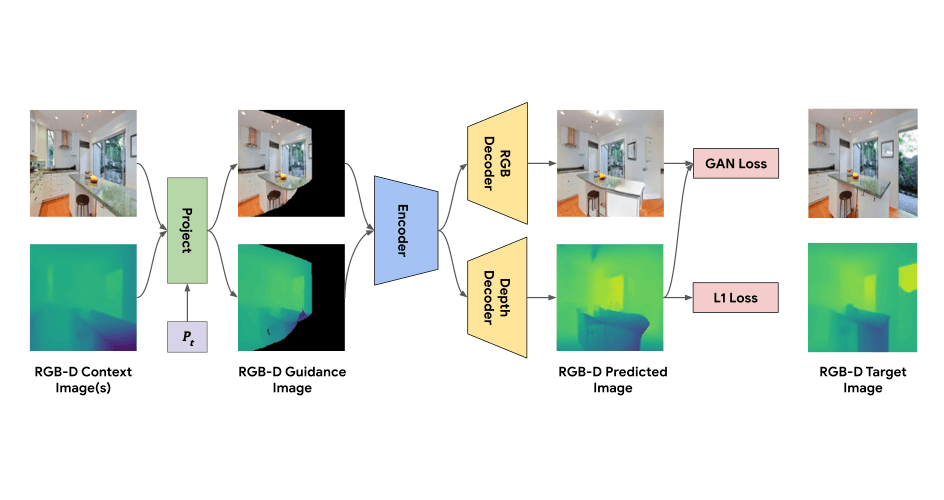
2022

2021

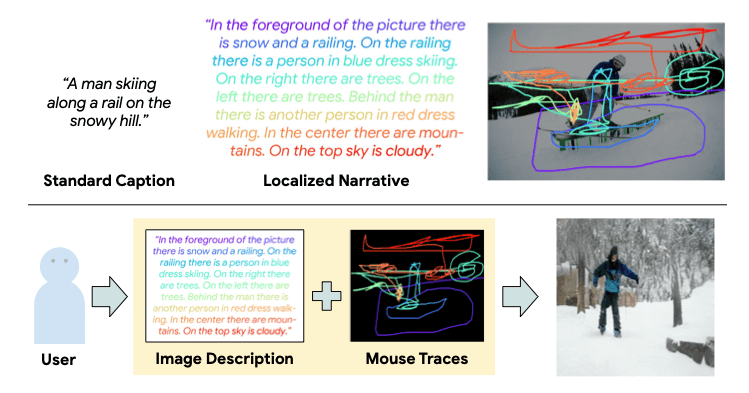
Text-to-Image Generation Grounded by Fine-Grained User Attention
WACV, 2021.